This article explains the different alternatives when using offline synchronization in the context of Offline Native Mobile applications architecture, given by the receive granularity criteria. In this context, the developer has two main options for synchronizing table's data from the server-side to the device (client-side): by table or by row. For this last option, there are also two flavors: by hash or by timestamp.
For simplicity, we'll refer to "rows" for those rows that satisfy the Offline Database Object conditions.
For each table involved in the synchronization, if the table was changed, it sends all table records from the server to the device.
On the device, for each table: if the table was modified, first all table records are deleted on the device, and then all the new values retrieved from the server are saved. If a table has not changed since the last synchronization, then nothing happens.
This mechanism significantly decreases the processing needed in the server (because there is no need to compare the table's records), but the data transfer may increase severely.
To enable the synchronization by table mechanism, select the value "By Table" in the Offline Database object's Data Receive Granularity property.
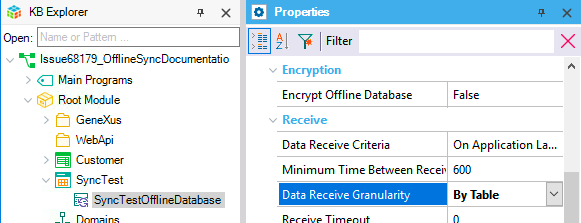
This algorithm is useful when the system has few rows in the table or on every synchronization the device must bring a high quantity of rows.
This solution avoids the expensive calculation of hashes for each row.
Using this solution when few rows change, always transfers all of them unnecessarily.
For each table involved in the synchronization, if the table was changed, it sends only the modified rows (inserted, updated or deleted) from the server to the device. Differences are computed by using row hashes.
To be able to use this mechanism, GeneXus needs to create some auxiliary tables in the server and to compute the MD5 hashes of the existing records in order to be able to find out new, updated, and deleted records. This requires more processing in the server, but may significantly decrease the data traffic.
To enable the synchronization by row using hashes mechanism, select the value "By Row" (default) in the Offline Database object's Data Receive Granularity property.
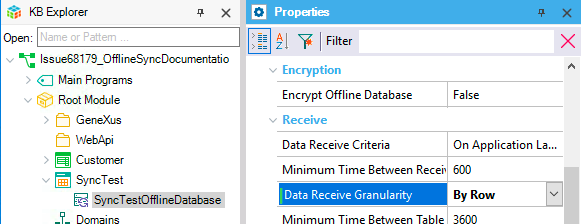
The synchronization by hash algorithm works as follows (for each table, on each device):
- The first time the devices synchronizes
- The algorithm determines the rows that need to be synchronized (all table records, filtered by the Offline Database object's conditions), computes a hash of the result set, and sends the data with the computed hash (used as an identifier) to the device.
- Also, a hash is computed for each row in the result set and stored along with the result set’s hash (the identifier sent to the device) and the row’s primary key in a table used specifically for synchronization
- Upon a new synchronization, the device sends the table’s hash to the server (the identifier received in the previous synchronization), and then the server:
- Determines the rows that need to be in the device (by querying the database and applying the conditions)
- Computes a hash of the result set
- If this hash matches with the hash sent by the device, it means that the table has no changes and then no further action is needed and the algorithm ends here
- If the hashes don’t match, then a hash is computed for each row in the result set, and compared with the hash of the previously synchronized hash for the same row, and then:
- If the row hashes’ match, the row has no changes and does not need to be sent to the device
- If the row hashes’ don’t match, the row has been modified and is sent as an update
- If the row didn’t exist in the previous result set, it is sent as an insert
- If the row existed in the previous result set and doesn’t exist now, it is sent as a delete
- The new table’s hash is stored in the server with the row’s hashes and the row’s primary key, to be used on the next synchronization.
This algorithm has several advantages when compared to other possible solutions. One of the main reasons to implement it this way was to avoid the modification of the model’s tables. By computing a hash and storing it outside of the Knowledge Base’s data model, there is no need to modify existing tables.
Another strong point in this algorithm is that it works regardless of how the modifications are made to the database. The hashes are computed at the moment the synchronization is performed, essentially using a snapshot of the current state of the database. How the database came to be in that state is irrelevant.
The main drawback of this algorithm is the performance when the datasets are too large. Especially when modifications are rare or synchronizations are very frequent. This is because on each synchronization the hashes of each row have to be computed on the new dataset. This operation may be time-consuming, and so it may not be the ideal solution in all scenarios.
The synchronization by timestamp algorithm uses a different approach. It still synchronizes by row, but it does not use hashes to compute the differences.
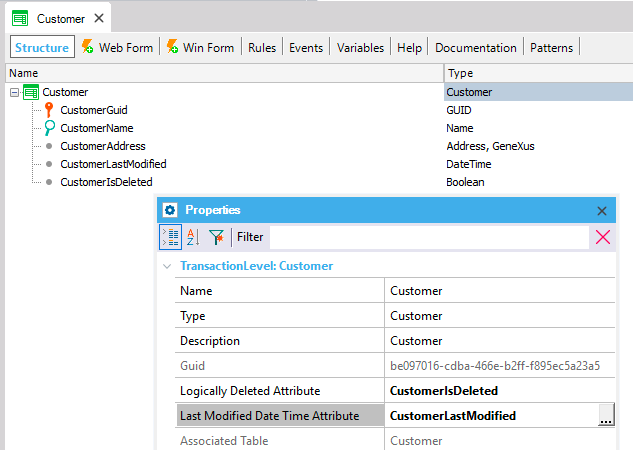
For this reason, the algorithm requires the addition of two attributes: the Last Modified Date Time attribute and the Logically Deleted attribute.
This algorithm can be applied on a per-table basis. Some tables may use synchronization by timestamp algorithm while others use the synchronization by hashes algorithm.
To enable the synchronization by row using timestamps mechanism, you first need to select the value "By Row" (default) in the Offline Database object's Data Receive Granularity property.
Additionally, for each table you want to synchronize by timestamp, you need to indicate the Last Modified Date Time and the Logically Deleted attributes on the Transaction's level properties as shown below.
- The first time a synchronization request arrives, the server sends all the table’s data matching the conditions -specified in the Offline Database object- to the device, along with the timestamp of the synchronization.
- The device stores this timestamp (to the device this is just an identifier), and uses it on the next synchronization, sending it to the server.
- On the next synchronization, the server has the timestamp sent by the device, so it uses this timestamp to compare with the value in the Last Modified Date Time Attribute. All rows modified or added after the last synchronization are considered.
- For each one of these rows:
- If the Logically Deleted Attribute has True value, the row is sent as a delete.
- Then, conditions from the Offline Database object are applied and:
- If the record matches the conditions, it is sent as an update (and treated as an upsert in the device),
- Otherwise, it is sent as a delete.
Note that the algorithm uses a "modification timestamp", that needs to be updated every time there is a modification. This action is the developer’s responsibility, if the record is modified without updating this value, the algorithm won’t synchronize it. Also, deletes need to be logical. If a record is physically deleted from the table, the algorithm won’t find it and it won’t be deleted on the devices. The developer is also responsible for prohibiting deletes and managing them logically instead.
The attributes defined in theLogically Deleted Attribute property and Last Modified Date Time Attribute property are managed by the developer. If they are not correctly maintained, the algorithm will not work as expected.
The algorithm does not keep track of deleted rows, as does the synchronization by hash algorithm. In that way, if a record is deleted from the table, the information will be lost and the delete will never be performed on the device.
There are some tables that are synchronized because they are referenced by a foreign key on another table. These tables cannot use the synchronization by timestamp algorithm.
For example, suppose you have a Customer table which has a reference to a Country. The Country table is not used in the smart device's application, it is used only to display the country name on the Customer detail. In this case, the only records from Country that get synchronized to the device, are those referenced by a Customer. The recordset needed by the device does not depend on the Country table, it depends on the Customers. If a new Customer is added that belongs to another Country, the Country record needs to be sent to the device regardless of its modification date. This is handled automatically by synchronizing the referenced table by hash.
In summary, referenced tables do not use timestamp mechanism (even if they were set as it). In such case, referenced tables synchronize by using hash default mechanism (with its advantages/disadvantages) regardless of synchronization date. The reason behind this fact is that referenced tables can change its state, and that state must be reflected on the extended information displayed by the table synchronized by timestamp.
The referenced tables limitation is actually a special case of tables with records’ conditions that depend on information not contained in the table being synchronized. It is not the only case though.
Suppose we have the following scenario: in our application, we have a Customer table and an Invoice table. We define that a Customer is active if it has an Invoice in the last 30 days, and we want the synchronization to take to the device only the active customers.
In this case, the synchronization by timestamp algorithm cannot be used on the Customer table, because the records to synchronize can change without modifying the table’s records. In fact, in this case, as the condition depends on the current date time, the records to synchronize can change without any change in the database.