By Breogán Gonda and Nicolás Jodal
Versión 1 - Montevideo, August 16, 2007
Relational Databases are particularly complex and difficult to understand. They were introduced by Edgar F. Codd in 1970 with two main purposes: simple data representation and powerful operators to handle this data simply and automatically.
Today all current business computing applications are developed around relational databases. But this was not always so.
The database concept and the first database management system were introduced by Charles Bachman in the first half of the 60’s decade. A few years later there were several database management systems in the market, based on different ideas and structures: there was a general trend towards casuistry.
The essential theoretical work on relational databases by Edgar F. Codd was published in 1970. But the generalized adoption of these relational databases did not take place until the first half of the 90’s decade.
Previously, data was stored in multiple files independent from each other and both the consistency control and the navigation from one data set to another were within the programs.
The major change was that a Relational Database is, in principle, a single place where data is placed and, at the same time, it describes this data and contains rules that must be observed to use it as well as operators that help when using them. That is to say, several important management tasks (ideally all of them) and data navigation tasks are automatically performed by the Database Management System and the developer does not have to be concerned with them.
GeneXus was built based on these ideas and its development has implied refining them and make them increasingly perfect.
In a Relational Database, data is stored in “Relations” that, for the purpose of this introduction, we will consider as tables. Each table has a group of columns, each represents different values of a specific uniform data element (with a well determined meaning such as: CustomerCode, CustomerName, ProductCode, ProductDescription), that we will call “Attribute”.
Each row combines values of different attributes. We can store all data using groups of these simple tables.
Let’s see an example:
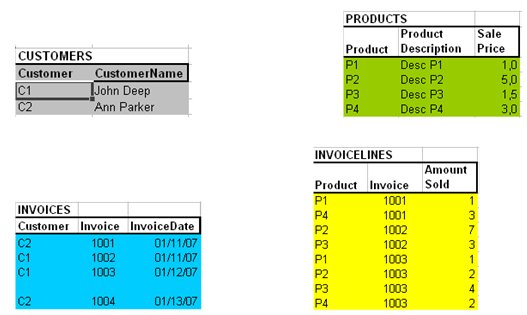
But we must not think in isolated tables (otherwise we would return to the time of independent multiple files). What is the essential difference between these “relational tables” and the independent files? Columns homogeneity around a well defined meaning for each of them, the fact that each column is externally described. But, will an attribute be present in just one table? In some cases it will, in other cases it will not. Let’s consider CustomerCode; finding this attribute in a table containing all Customer data seems reasonable. At the same time, the fact that CustomerCode identifies this table also seems reasonable, since there is no more than one row with the same CustomerCode value. In this case, we say that CustomerCode is the “key” of the table that contains customers fixed data, a table that, for instance, we will call “Customers”.
The fact that there is no more than one table to store Customers fixed data also seems reasonable: there won’t be more than one table with the same key.
But there will be other tables where the CustomerCode attribute will appear; e.g.: the one where invoices are stored. Each Invoice will be linked to a Customer and, how does this link operate? It operates through CustomerCode.
We can see then that some attributes can appear in multiple tables. These attributes that appear in more than one table will be called primary attributes.
The fact that some attributes may appear only in one table also seems reasonable (let’s say that CustomerName only appears in the Customers table). These attributes that appear only in one table in the entire database will be called secondary attributes.
Usually, a model has semantic elements and syntactic elements. Operating with syntactic elements is easy but, how could we represent semantic elements so that operating with them would be easy also? In other words, how could we represent semantic elements through syntactic elements? A good option is representing attributes meaning through their names. For this, a suitable assignment of names to attributes is essential.
How should we assign names to attributes? The essential premise is that the assigned name must represent the attribute meaning suitably and as independently as possible to the place where it appears in the Database.
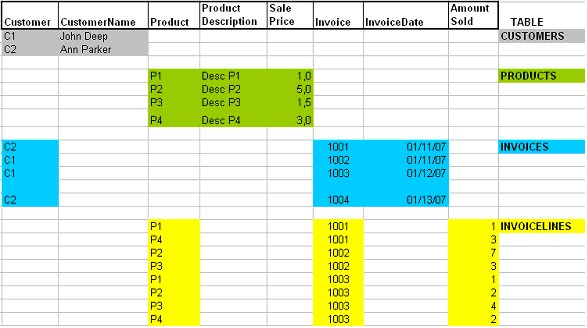
Let’s say that there is a super table that contains all the tables of our Relational Database. Since we will actually need multiple tables in our database, this super table will not be dense or homogeneous, but each column will always respond to an attribute. Somehow, we will associate a meaning to each column, and this meaning will be the same for all the tables where this column is involved.
Our purpose is that a specific attribute will have always the same name, regardless of the place where it appears, and that there won’t be two different attributes with the same name. This is the essence of URA and constitutes an excellent base to establish an attributes nomenclature. GeneXus assumes the use of URA (strictly speaking, of an expanded URA).
Let’s see an example of URA
Edgar F. Codd’s works introduce Normalization to avoid certain anomalies and allow a problem-free representation. Data may not match any formal form or they may be in 1st Normal Form or in 2nd Normal Form or in 3rd Normal Form. The best option is for data to be in 3rd Normal Form. From now on, by “normalizing data” we will mean representing it in 3rd Normal Form.
But, what is the essence of normalization? It consists of achieving a non-redundant data representation. If the representation is redundant, there will be two or more versions of the same data item and, if there is no robust control over this, an inconsistency will inevitably occur and there will be several versions of the same data item with different values. The purpose of normalization is that each data item will have only one version and that any data item that can be inferred from the rest of the stored data will not be stored.
This is all we need to know about normalization. And, how should we perform it? GeneXus performs it automatically and with no work for us.
We have said that our Database is made up of a group of tables. And, how do these tables relate to each other? They relate through the values of their primary attributes.
If we look at the example we have introduced to explain the URA, we will see that each Customer appearing in the Invoices table also appears in the Customers table, each Product appearing in the Invoice Lines table also appears in the Products table and each Invoice appearing in the Invoice Lines table also appears in the Invoices table.
None of this is casual. If there is an Invoice involving a Customer that is not catalogued in the Customers table, an inconsistency will occur (and the same will occur in the other examples). All this is comprised in a fundamental consistency law that we can state as follows:
If attribute A is key of a specific table T1 and it also appears in another table T2, for a specific T2 line to exist there must be a line in T1 with the same value as A.
In the examples, we have considered simple attributes but all of the above is also valid for compound attributes.
These referential integrity rules must be observed to ensure model consistency.
The entire theory expressed above is basically owed to Edgar F. Codd. Nevertheless, Codd has omitted two essential things in his fundamental works:
- The introduction of the URA. The URA concept is essential to Codd’s relational theory. Probably, it was so evident for him that he did not state it.
- Likewise, for reasons not so easy to understand, Codd did not introduce the concepts of Referential Integrity in his fundamental works. Several years later he did introduce them, but empirically, without using the simple referential integrity rule that we have stated.
We can say beyond any doubt that Codd’s main objectives were obtaining a simple data representation and providing operators to handle this data automatically. GeneXus implements these operators automatically.
Building GeneXus has demanded some expansions upon the relational theory, which of course is totally consistent with it.
There are basically three expansions: URA expansion to allow representation of Subtypes, Introduction of Formulas and Introduction of Redundancies.
We often find specific attributes, such as AirportDeparture, AirportArrival that have a well determined concrete meaning but, at the same time, are particular cases of a more general attribute (Airport). We could say that they have the same basic meaning and therefore we are talking about the same attribute in different roles but, what could we say when two or more of these attributes appear together? We would not be able to work unless we differentiate them. Therefore, we will say that AirportDeparture is a Subtype of Airport and that AirportArrival is a Subtype of Airport. This concept of subtypes is not limited to atomic attributes; it can be applied to groups of attributes.
If, for instance, InvoiceLineValue = AmountSold * SalePrice and InvoiceSubTotal = ? InvoiceLineValue, should we store InvoiceLineValue and InvoiceSubTotal in the Database?
We need a representation that must be as complete as possible, but always consistent.
If we do not have formulas, the answer is: yes, we must store them.
If we work at a higher level and have formulas in our model, neither InvoiceSubTotal nor InvoiceLineValue must be stored, since the system is capable of calculating them when necessary (and the stored values would be redundant regarding those we can calculate any time and could even be inconsistent with them.)
GeneXus introduces an extensive and powerful group of formulas.
Are redundancies good or bad? According to what we have seen so far they seem to be bad (since they are a source of inconsistencies). Actually, redundancies are neither good nor bad. “Uncontrolled redundancies” are the bad ones. If we explicitly assume a redundancy and establish control mechanisms so that data remain always consistent, this redundancy will not have bad effects.
Could a redundancy have good effects? We can think that having an attribute stored will save us the time to calculate it. But sometimes, this time is irrelevant; e.g.: storing the InvoiceLineValue attribute as redundant just for saving us the calculation of InvoiceLineValue = AmountSold * SalePrice does not seem reasonable with today’s technology (although it would’ve been useful 40 years ago, when a mathematic operation, in spite of being as simple as this one, took a significant time). But a completely different case is storing InvoiceSubTotal = ? InvoiceLineValue as redundant. If this attribute is used with a certain frequency and the number of elements summed up is high (we must access many records to perform the sum) keeping it redundant can be quite useful.
How does GeneXus deal with redundancies? GeneXus allows us to introduce certain redundancies. Once we have done this, GeneXus becomes responsible for maintaining the consistency of each redundancy and takes advantage of each of them when suitable to improve performance.
Codd opted for explicit operators that are quite powerful but require a thorough knowledge of the Database by the user. At that time, this was possible because databases had few tables, but with large databases nowadays it would be impracticable.
Using SQL language syntax (Structured Query Language, developed by IBM directly based on Codd’s works), let’s return to the example seen to introduce the URA and let’s say that we want to list for each customer his invoices and for each invoice its lines. We should do something like the following:
Select Customers.Customer, CustomerName, Invoices.Invoice, InvoiceDate, Products.Product, ProductDescription, AmountSold,
From Customers, Invoices, InvoiceLines, Products
Where Customers.Customer = Invoices.Customer and
Invoices.Invoice= InvoiceLines.Invoice and
InvoiceLines.Product = Products.Product
Order by Customer, Invoice, Product
This way of writing is too heavy (with Select we state the output columns, with From the tables where data must be obtained, with Where the way in which tables must be combined and with Order By the output order) and users will have no possibility of writing these queries if the database has 1000 tables instead of a few tables.
With the concepts we have introduced here, the above can be written in a very simple way:
Select Customer, CustomerName, Invoice, InvoiceDate, Product, ProductDescription, AmountSold.
Order by Customer, Invoice, Product
where we simply list the output columns in the order we want and we determine the order of the lines in this output column since the system knows all the rest.
In GeneXus, we opted for high-level implicit operators that allow writing queries in a very simple way and allow these queries to be independent of the tables where data resides. We never refer to tables; the system determines the tables to be used at generation time. This is a very important feature since Databases are never stable, there are always modifications and frequently an attribute moves from one table to another. GeneXus query specification will remain valid, SQL specification will not.