Azure Cosmos DB is Microsoft's fully managed and serverless distributed database for applications of any size or scale, with support for NoSQL.
As it is a NoSQL database, it has some peculiarities which have to be considered when using it in your solution. The following is a brief guide of these particular features, but it is also recommend checking the Azure Cosmos DB documentation.
Summary
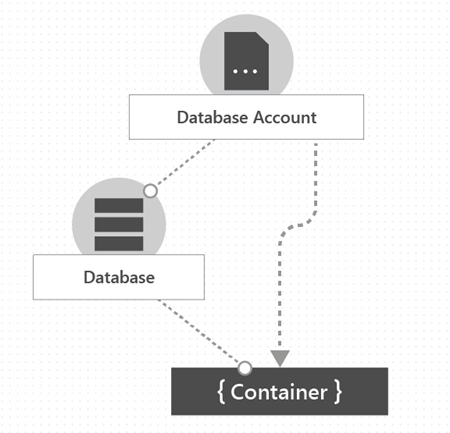
The CosmosDB resource model is as follows.
The unique identifier is a distinct string that identifies an item within a container. The id property is the only required property when creating a new JSON document. The id property is case-sensitive. (ref)
The uniqueness of the id property is only enforced within each logical partition. Multiple documents can have the same id property with different partition key values.
"Azure Cosmos DB uses partitioning to scale individual containers in a database to meet the performance needs of your application. In partitioning, the items in a container are divided into distinct subsets called logical partitions. Logical partitions are formed based on the value of a Partition Key that is associated with each item in a container. All the items in a logical partition have the same Partition Key value." (ref)
Choosing a partition key is an important decision that will affect your application's performance. Check the Azure documentation.
Note: Your partition key should:
- Be a property with a value that doesn't change. If a property is your partition key, you can't update that property's value. That is, it's part of the Primary key of the table.
- Only contain Double, String or Bool values - numbers should ideally, be converted into a String.
Important: GeneXus does not allow to represent double values (only decimal values), see Attribute and Variable Data types mapping by Generator. So, to have double type partition keys, a conversion is done from the decimal value, which, in some cases may lose precision.
Combining the partition key and the item ID creates the item's index, which uniquely identifies the item.
In conclusion, the primary Key of the transaction must be composed of:
- A string attribute whose external name should be "id". This should be the first attribute of the Transaction, and of the dataview associated with the Transaction.
- An optional attribute (string or number) that will be the Partition Key.
The partition key can be the same as the id, so it's not mandatory to define it. See Use Item id as the Partition Key.
Azure Cosmos DB by default automatically indexes every property for all items in your container without the need to define any schema or configure secondary indexes.
There are three types of indexes, explained in detail here.
Range indexes can be used on scalar values (string or number). The default indexing policy for newly created containers enforces range indexes for any string or number.
If your workload is write-heavy or your documents are large, you should only index necessary paths. This will significantly decrease the amount of RUs required for inserts, updates, and deletes.
An ORDER BY clause that orders by a single property always needs a range index and will fail if the path it references doesn't have one.
Composite indexes increase efficiency when you are performing operations on multiple fields.
An ORDER BY query that orders by multiple properties always needs a composite index.
Otherwise, the cosmos engine throws an error:
BadRequest (400); Message: {"Errors":["The order by query does not have a corresponding composite index that it can be served from."]}
"With unique keys, you make sure that one or more values within a logical partition are unique. You can also guarantee uniqueness per partition key." (ref )
"For example, consider an Azure Cosmos DB container with an Email address as the unique key constraint and CompanyID as the partition key. When you configure the user's email address with a unique key, each item has a unique email address within a given CompanyID."
So, the partition key combined with the unique key guarantees the uniqueness of an item within the scope of the container.
Cosmos DB is a schema-free database whose data is represented as self-contained items represented as JSON documents.
Regarding that, there is no relational integrity; some strategies exist to model your data.
By now, GeneXus only supports flat structures (denormalized structures).
A logical partition consists of a set of items that have the same partition key. (ref)
Azure Cosmos DB supports JSON types, such as string, number, boolean, null, array, and object.
However, you can use other types in your application, such as a date data type (which under the hood will be sent as strings).
The recommended format for DateTime strings in Azure Cosmos DB is ISO 8601 UTC standard. It is recommended to store all dates in Azure Cosmos DB as UTC. (ref). For more information on java, see CosmosDB date and datetime handling.
By now, GeneXus supports all data types except for array and object.
For the case of Images, you must store the external storage URI of it, instead of storing the image itself.
In Azure Cosmos DB, joins are scoped to a single item. Cross-item and cross-container joins are not supported.
By now, GeneXus does not support embedded structures, so Joins for single items are not supported either.
By now, GeneXus does not support Transactional batch operations for Azure Cosmos DB.
For the time being, concurrency control is not implemented. So, there is no check before updating, if there was an operation that modified the data after having read it for update.
Items are stored as JSON values. These JSON values are case-sensitive.
How to model and partition data on Azure Cosmos DB using a real-world example
Create a synthetic partition key
Indexing in Azure Cosmos DB