This strategy aims to improve the accuracy and context of retrieved content by balancing the use of smaller and larger text chunks during ingestion and synthesis.
The default ingestion process embeds a large text chunk for retrieval and uses the same chunk for synthesis. This approach can sometimes lead to inaccuracies and lack of context.
The Parent Document strategy addresses these limitations by:
-
This allows for more precise semantic similarity matching based on user queries. Smaller chunks are stored in a vector store. These smaller chunks are called childDocuments. They are expected to contain information at the paragraph level.
-
This "parent" document, which can be a partial or complete document, is stored in a document store. This larger chunk is called parentDocument. It is expected to preserve a broader scope of information.
-
This ensures that the retrieved context is comprehensive and semantically rich, allowing the LLM responsible for synthesis to perform better.
-
Smaller chunks (childDocuments) allow for more accurate matching based on user queries.
-
Larger parent documents (parentDocuments) provide a broader understanding of the retrieved content.
-
The LLM has more context to work with, leading to more accurate and relevant responses.
Chunking is a balancing act. You want to:
- Split documents into small chunks: This improves semantic similarity but can lead to loss of meaning or context.
- Keep documents long enough: This preserves context and semantics, but may not be as accurate for similarity matching.
The Parent Document strategy strikes this balance by using small and large chunks (childDocuments and parentDocuments). Small chunks are good because embeddings accurately reflect meaning and relevancy; parent chunks are good retaining context for the generation phase. The technique means:
- search for smaller context information
- return big context
To enable the Parent Document strategy, configure the following settings:
- useParentDocument: Set this boolean parameter to true in the Profile Metadata.
- Parent configuration: Configure the parent chunking strategy in the Index Section.
- ChildDocument configuration: Configure the child chunking strategy in the Profile Metadata.
The parent chunking strategy must be configured using the following parameters in the Index Section:
| Parameter |
Description |
| ChunkSize |
The size of the parent document chunk in characters. The default value is 1000 characters. Consider increasing this value to 5000 or 10000 characters when using the Parent Document strategy. |
| ChunkOverlap |
The overlap between parent document chunks. |
The child chunking strategy must be configured using the following parameters in the Profile Metadata:
| Parameter |
Description |
| childK |
Parameter to search for documents in the VectorStore based on customer query. This does not exactly correspond to the number of final documents retrieved, as multiple child documents can point to the same parent. This upper-bound parameter is set by the k parameter (Document Count) and limits the number of final documents returned. |
| chunkSize |
Size of the chunk in number of characters. |
| chunkOverlap |
Overlap between child chunks. |
| contentProcessing |
Defines how the child chunk content is treated. Use '' (to keep the associated text on the vectorstore; is the default value) or 'clean'(1) not to store the text repesentation on the VectorStore. |
The default configuration stores:
- Textual information for the parent chunk documents on the Globant Enterprise AI Backoffice.
- Textual information for the child chunk documents on the VectorStore.
When using the clean option, only the associated embeddings and metadata for each element are stored on the VectorStore.
(1) - The
clean option cannot be used in conjunction with a
reranker.
- Ingestion Cost: The Parent Document strategy can increase ingestion time due to the additional processing required.
- Child Chunk Size: You can use chunk sizes between 300 and 800 characters for splitting child documents.
- Ingestion is mandatory: If you enable the Parent Document strategy; a reingestion of all documents is mandatory. It is recommended to clean your assistant and reingest.
A valid configuration to be used with the RAG Assistant API to create an assistant with the ParentDocument strategy could be the following:
"indexOptions":{
"chunks":{
"chunkSize": 8000,
"chunkOverlap": 0
},
"useParentDocument": true,
"childDocument": {
"childK":20,
"child":{
"chunkSize":300,
"chunkOverlap":50,
"contentProcessing": ""
}
}
....
To activate the Parent Document strategy in the RAG Assistant in Globant Enterprise AI Backoffice, first, go to the RAG Assistant row where you want to apply this strategy. Once there, click on UPDATE to open the Assistant settings and select the Retrieval tab. In this section, add the following settings in the Profile Metadata field:
{
"chat": {
"retriever": {
"useParentDocument": true,
"childDocument": {
"childK": 20,
"child": {
"chunkSize": 300,
"chunkOverlap": 50,
"contentProcessing": ""
}
}
}
}
}
The setting "childK": 20 defines that 20 child chunks will be considered for each query, while "chunkSize": 300 states that each chunk will have a size of 300 characters, and "chunkOverlap": 50 indicates that there will be an overlap of 50 characters between consecutive chunks. There is no processing (contentProcessing) for the child chunk content.
Next, in the Index section, configure the following:
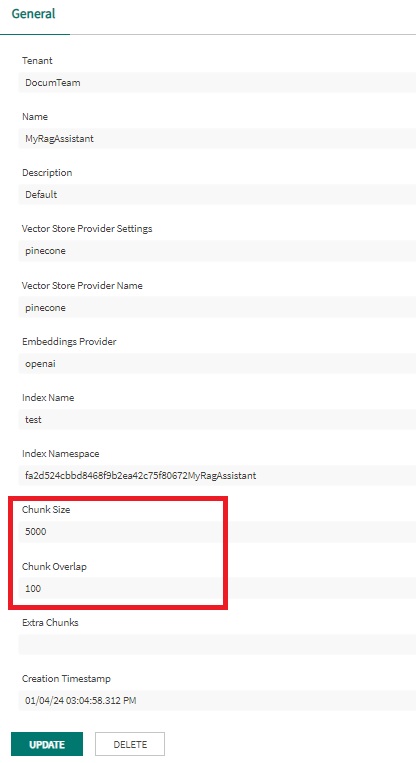
This setting is aligned with the strategy of handling long documents (Chunk Size of 5000 characters) and captures a larger amount of relevant content through a higher overlap (Chunk Overlap of 100 characters). This is good for optimizing both performance and retrieval accuracy, but it is always advisable to adjust these values according to the specific needs and results observed in the context of your application.
RAG Assistants API